
Solution and Objectives
Quantimodo tapped our team to architect this new category of analytical wellness platform. We embarked on a 9-month partnership to design, build, and launch what would become the category's first comprehensive personal optimization engine based on aggregated tracking data and applied AI:
- Construct APIs and pipelines to continually ingest fitness, health, sleep, diet, and other self-monitoring data from wearables, medical devices, and 50+ popular tracking apps used by millions.
- Engineer a cloud analytics architecture to structure and store composite historical tracking data from authorized sources in a privacy-centric data warehouse designed for analytical optimization modeling.
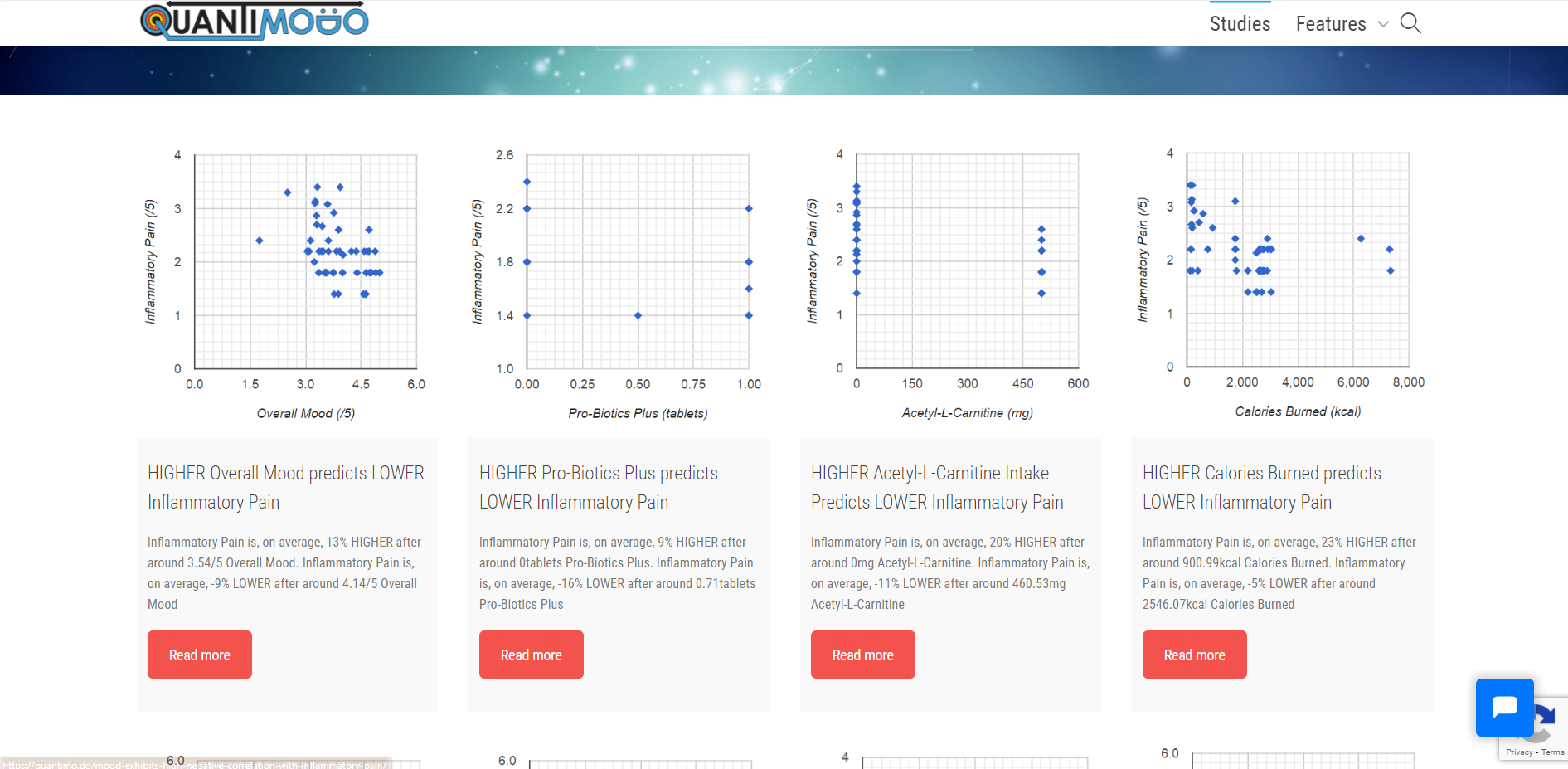
- Develop machine learning algorithms able to analyze full spectrum personal data history to uncover subtle multivariate relationships between potential causal intervention factors and measurable downstream indicators or symptoms in an individual's base set.
The ultimate aim was empowering consumers with previously impossible visibility into what unique lifestyle adjustments, up to 300+ parameters, could positively drive outcomes most relevant to each user based on their own master dataset.
Technology Planning
After initial product scoping, our team worked closely with Quantimodo executives to align on optimal technology for each platform component considering required capabilities, scalability objectives, and internal skillsets.
Key technology decision drivers:
- Pipe-and-filter-based architecture: needed high flexibility to add new data sources to the automated ingestion workflow plus accommodate exponential data growth.
- Cloud-native tech stack: required dynamic storage and compute ability to run advanced analytical algorithms leveraging AI and ML methods at scale.
- API-driven connections: centralized credentialing and connectivity with 3rd party apps/devices were mandatory to enable access to user self-tracking data flows across platforms.
- Privacy and compliance: top factor given sensitive user health data requiring controls like consent flows, access restrictions, and data locality.
Final platform technology blueprint:
- Automated API Integration Hub: Node.js microservices and serverless functions on AWS Lambda powering 3rd party connectivity.
- Cloud Data Ingestion Pipeline: Apache Kafka manages ingestion queues, data parsing/validation functions, and routing by source.
- AWS Managed Databases: Timestream DB for time series storage optimized for date-attribute analysis plus DocumentDB for unstructured data.
- Applied Machine Learning: Jupyter Notebooks tapping SciKit Learn framework plus custom methods to uncover personalized correlations.
This combination allowed for maximizing automated ingestion capacities and analytical model development/computation leveraging cloud scalability while ensuring air-tight data governance.



